我们生活在信息爆炸的时代,网页上充斥着各种各样的数据和内容。在这样的背景下,爬虫软件应运而生,成为我们获取信息的一大利器。简单来说,爬虫软件是一种能够自动访问互联网并提取所需数据的程序。它的主要功能是浏览网页,抓取网页中的文本、图片、链接等信息,并保存到本地,这样我们就能在本地进行分析与使用。
爬虫软件的应用场景非常广泛。如果你是一名研究人员,可能需要收集大量的学术文章和数据;如果你经营一个电商平台,爬虫软件可以帮助你获取竞争对手的价格信息、产品描述等;甚至如果你是在进行市场调查,爬虫软件能够帮助你分析社交媒体上的公众舆论。无论你的需求是什么,爬虫软件都能以高效、便捷的方式满足你的信息采集需求。
至于爬虫软件的工作原理,它通常是通过模拟人类的浏览行为来进行数据收集。当你输入一个网址时,爬虫软件会发送请求给该网站的服务器,并获取页面的HTML内容。接着,软件会分析该网页的结构,提取出其中有价值的信息。这个过程往往会涉及到解析、过滤和存储等多个步骤。看似复杂的过程,其实在技术的支持下已经变得相对简单,让我们可以轻松获取到需要的数据。
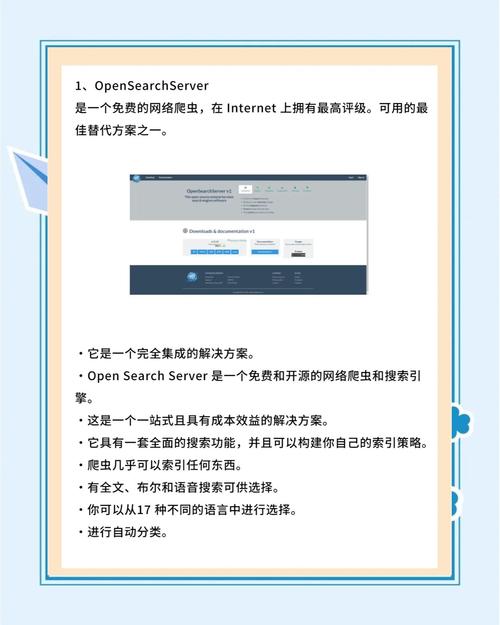
在信息获取的旅程中,选择合适的爬虫软件至关重要。市面上有许多不错的免费爬虫软件可供使用,每款软件都有自己的特点和优势。对于我们这些非专业程序员或刚入门爬虫领域的人来说,找到合适的工具可以显著降低学习曲线,让数据的收集变得更加容易。
首先,我想介绍一下Scrapy。这是一款功能强大且广泛使用的开源爬虫框架。它适合大规模的数据抓取,操作起来也相对灵活。Scrapy支持异步处理,能够高效地抓取大量数据,非常适合需要进行复杂数据采集的用户。对于初学者来说,Scrapy的文档也非常详细,学习起来不会太复杂。
接下来是Beautiful Soup。这款工具以其易用性著称,特别适合用于从HTML和XML文档中提取数据。如果你只是想快速抓取一些小范围的信息,Beautiful Soup是一个很好的选择。它具有强大的解析能力,能够处理一些结构混乱的网页内容。我的个人经历是,用Beautiful Soup抓取某个网页的表格数据时,简直是轻而易举,让我称赞不已。
还有一个值得注意的软件是Selenium。它与其他爬虫软件不同,Selenium可以模拟人类在浏览器中的操作。这使得它特别适合抓取那些需要进行用户交互的网站,就像当用户登录时需要输入验证码的网站。我的一位朋友用Selenium成功提交了网上调查表,获得了数据,非常好用。
最后,ParseHub也是一个不容忽视的选择。它提供了一个可视化的界面,让用户通过点击的方式来抓取数据,对于没有编程背景的人来说,这简直就是神助攻。我们可以通过拖放元素来定义抓取规则,轻松提取网站的数据。不管是新手还是有一定经验的用户,都能从ParseHub中获得乐趣。
在选择适合自己的免费爬虫软件时,有几个因素需要考虑。首先,明确自己的需求,了解你需要抓取的数据类型和数量。其次,考量软件的用户友好性,是否有良好的文档和社区支持。最后,根据你自己的技术水平选择合适的工具。如果你习惯编码,那么Scrapy可能更适合你,而如果你喜欢可视化操作,ParseHub则是一个理想的选择。
使用这些免费爬虫软件之前,安装过程也很重要。一般来说,Scrapy和Beautiful Soup需要使用Python环境,这对初学者可能稍有挑战。不过,网上有许多详细的安装教程,只需要谨遵指示,配合正确的Python版本,问题通常不大。Selenium和ParseHub的安装步骤相对简单,尤其是ParseHub,基本上只需下载软件并注册一个账户即可开始使用。
总之,免费爬虫软件为我们提供了一个便捷的途径去获取和分析数据。在出发前,了解自己的需求,并尝试一下不同的软件,总能找到最适合你的那一款,让你的数据之旅更加顺畅。